
先日、Dr. Herbert StoneによるQDAワークショップを開催致しました。Stone先生と一緒に仕事をし始めて10年以上になりますが、官能評価の認知や向上に懸ける強い思いは相変わらずで、精力的な活動に大変頭が下がります。今回も多くの皆様にご参加頂き、ありがとうございました。QDAに関して、より理解を深めて頂ければ幸いです。
さて、QDA法のデータをとったあとの解析は、一般的に難関のようです。今回のワークショップのアンケートでも、難しいという声が多かったです。
分散分析
QDAデータの解析には、基本記述統計のほか、分散分析と多重比較検定、それに多変量解析(主成分分析など)が行われます。機器分析データがあれば、各属性との相関を求めたり、あるいはQDAデータと分析データを組み合わせ、回帰分析で消費者の受容度の予測モデルを構築したりすることも可能です。それによって、官能評価の負担を軽減させられ、さらに客観性が高まるので、企業にとっては大いにチャレンジする価値があります。
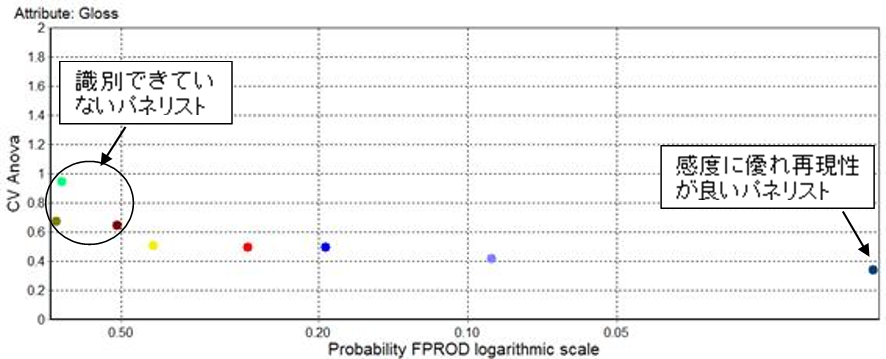
とはいえ、QDAデータの解析のコアとなるのは、何と言っても分散分析です。まず、一元配置分散分析で、パネリストのパフォーマンスを評価します。下図のグラフ(FIZZにより出力)は、属性「つや」に関して、パネリストの識別感度を示すp値(横軸)と、繰り返し評価の変動を示すCV Anova(縦軸)をプロットしたもので、右下にプロットされるパネリストほど製
品間のつやの違いを識別しており、かつ評価の再現性が良いことを示します。識別の目安をp値で最大0.5としたとき、つやを識別できていないパネリストが3名いることが分かります。
しかし、パネリスト一人がすべての属性に関する違いを検出できることは期待されません!そのために、約12名ものパネリストを使うのです。また、すべての属性で、サンプル間の違いが検出されることも期待されません。属性は十分理解されていたのか、サンプル間に本来差があったのかについて、次の試験前に再度ディスカッションを行うことが現実的です。

